Analytics Blog

Mine Customer Insights using Natural Language Processing in BigQuery
Google has been steadily improving and positioning its cloud platform offerings as viable contenders for your ever increasing needs for data science tools and technologies. To help enterprises accelerate their digital transformation and optimize their customer experience, Google is focusing its pre-built use cases on digital commerce and smarter marketing with the Google Cloud for Marketing platform. BigQuery has always had tight connectivity with Google Analytics data, and now more frequently, organizations are bringing in additional data at the customer level to build rich customer profiles.
It only makes sense that, if BigQuery is evolving within your organization as a hub for additional data, gaining insight from natural language processing (NLP) text will soon be on your radar. This encompasses:
- Voice of the customer
- Frequently asked questions
- Feedback from satisfaction surveys
- Social comments
Most businesses don’t think about BigQuery as being data science-friendly, but Google announced BigQuery ML in 2011, so it’s not a new idea. BigQuery machine learning capabilities will certainly become more commonplace as more businesses are exploring niche data for additional insight.
“BigQuery machine learning capabilities will certainly become more commonplace as more businesses are exploring niche data for additional insight.”
Customer Opinions are What We’re Looking For
If you have the opportunity to look at the stream of raw text data gathered from an open-ended text form on your website, I think you’d be overwhelmed and likely frustrated. Some of the entries will seem clearly important and offer great customer insights, while others will be ramblings. What we’ll recognize is the need to quantify and put structure around textual entries. We need to classify entries according to a set of rules, and we’ll need a methodology to analyze textual data to calculate a weight of importance.
Think of it this way: if you have the bandwidth to only read 10 customer feedback reviews, wouldn’t you want them to be the ones with the most insightful information? We must consider a methodology to “rank order” all the responses so we can focus on the right ones first.
Understanding Natural Language Processing (NLP)
A common approach is to measure sentiment – mining the opinions for their underlying meaning within text phrases being positive or negative in nature. The process often starts by breaking down phrases into individual words, a process called “tokenization.” The idea is to see if specific words (tokens) indicate if a phrase leans towards one of those two categories (positive or negative).
To tackle analyzing text data, we need examples of phrases that fall into these two categories. Gathering training data is common practice for machine learning systems to weigh and quantify individual words. There are a couple of areas where common mistakes are made: not using proper definitions of positive and negative for the data set you are trying to analyze and not having significant yet diverse training data.
Let me demonstrate why selecting good training data is critical. Let’s assume for a moment the text we are gathering from your clients was in response to the question “How Can We Improve Our Website?”
Consider the following example text responses:
- “Your product search feature doesn’t work.”
- “I’m very happy with your site.”
- “Where is the password reset?”
- “Why don’t you answer my phone calls?!!!”
Think about positive relative to the question asked. Ideally, the response provided should directly guide you towards ways to improve your website. I’ll argue #1 and #3 are positive in that they are pointing out areas that need improvement. Visitors were struggling with specific features, and you need to know this. While we all love to see #2, that response really doesn’t help us. It’s negative based on the fact it doesn’t help answer the question. Response #4 is somewhat neutral by our definition, and therefore we should leave this type of response out of any training data an NLP tool might see..

Onward to BigQuery
The size of your tables might be tens of thousands of entries depending on your overall site traffic. I created a table for raw entries plus a table each for known positive and known negative feedback. I kept the training tables separate knowing they might be used again for a different set of raw responses and to be able to update them over time with newer entries. Be sure you have plenty – several hundred – identified entries in these tables in order to avoid classification bias. The training data needs to represent a wide variety of real cases and not reflect internal prejudices.
Finally, I added a stop words table. This table allows for the removal of specific words from the natural language processing modeling effort. You can research this concept yourself, but the underlying concept is words like “I,” “we,” and “and,” do nothing to assist in the machine learning process.
The BigQuery commands for creating a new model are not your typical SQL. I needed to pass the modeling function a series of rows containing individual words and an associated label – the known positive or negative classification.
It takes a minute or so to run this query, then a new object will show in your project. Clicking on the object gets you run details and various measurements of the model’s quality. The modeling effort information provided is good, but certainly not the type detail we can adequately cover in this blog post.
Using the Model to Unveil Insight
With a model now created, the task we must complete before we can see those “top 10 most insightful comments” in the data is to apply the model. A point of clarification is needed here: The model I built uses predictions at the individual word level. What I want to evaluate is a full sentence, which means I’ll end up with a series of score values at the word level for every sentence.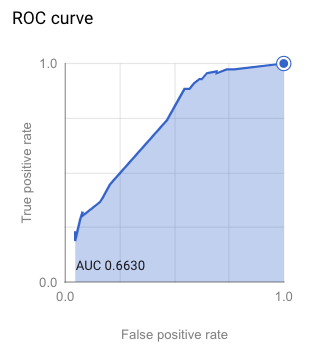
Therefore, the SQL to calculate a score for any one sentence must:
- Break the sentence down into individual words, removing stop words
- Calculate the contribution values for each word
- Calculate an average value based on the scored words within a sentence
Results and Marketing Insights
With the end result from my modeling steps completed, I printed out the top five sentences based on the highest score values. I found the results actually insightful, with the top suggested web improvements all being relatively reasonable, indicative of problematic areas – empirically calculated, ready to be presented in a dashboard for review.
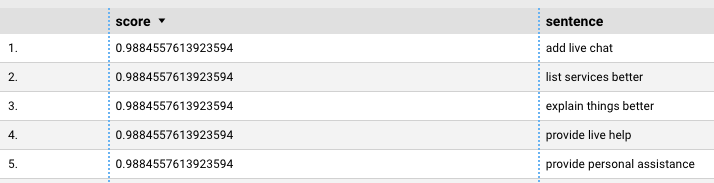
I noticed the top five scores all had the same value and all had three-word sentences. This meant the sum of the individual word scores were all equal. I needed to perform a quick sanity check.
I ran a quick distribution of counts of words and the corresponding predictive values. The encouraging news here is the list of individual words was still more than 10,000 rows long, with some words having the same predictive value and others standing out as uniquely contributing. This means my spread of possible scores is very wide – ultimately effective at rank ordering an entire sentence.
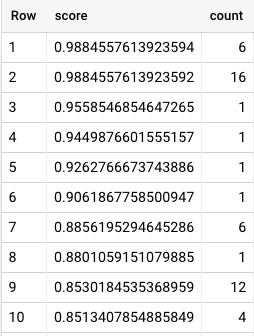
BigQuery Powers Customer Insights
Classification and regression work are commonly used to transition raw data into deterministic insight. What I learned by using BigQuery ML is that it too has viability as a data-science-ready contender.
As you consider bringing in additional data to enrich your customer profiles within BigQuery, or as you explore niche data to bring into various marketing insight tools, know that each provider will be integrating data science tools and capabilities tightly. I was quite surprised and pleased using BigQuery, as my results were exactly what I hoped for.
![]() Bottom line: BigQuery ML pulled its own weight and helped uncover the customer insights I was looking for.
Bottom line: BigQuery ML pulled its own weight and helped uncover the customer insights I was looking for.


If you have questions or you’re ready to discuss how Blast can help you EVOLVE your organization, talk to an Analytics Consultant today.
Call 1 (888) 252-7866 or contact us below.


